
When I was looking for some information about deep learning for the first time I noticed that there is a little confusion when someone tries to explain what deep learning is in fact. It is commonly said that it relates strictly to neural networks, whereas some claim that such statement might be misleading, because in fact there is much more than merely neural networks. In my opinion it brings a lot of confusion for a beginner. I will try to describe different definitions that can be found on the internet as well as in literature. I hope it will give you a big picture on what deep learning really is.
Table of Contents
Deep Learning Origins
What's Deep in Deep Learning
Is It Just About Neural Networks?
Summary
Further Reading
References
Deep Learning Origins
There is no doubt that it all started with human brain fascination and desire to understand how the brain works. For centuries people wanted to understand how our brain works and the earliest study of nervous system dates to ancient Egypt. I mention about it because this fascination initiated the development of neural networks - a desire to create a system that can simulate a human brain. Ok, please put yourself at ease, because to be honest, we still don't know many things about our brain and today's neural networks not necessarily are designed to resemble it.
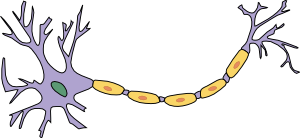
Figure 1. Neuron - the primary component of the central nervous system, including brain and spinal cord. It is an electrically excitable cell that receives, process and transmits information through electrical and chemical signals. Neurons can connect to each other to form neural networks.
(definition from en.wikipedia.org/wiki/Neuron)
It is widely considered that the pillars of artificial intelligence were placed by Warren S. McCulloch and Walter Pitts in 1943 1. These guys, in their paper 2, came up with a simplified mathematical model of a neuron. This model was the Threshold Logic Unit, which takes some binary numbers on input and outputs 1 or 0. McCulloch and Pitts neuron (MCP) was the first computational approach to neuroscience.
The next worth noticing date is 1949 when Donald Hebb published his work "The Organization of Behavior" where he stated following rule:
"When an axon of cell A is near enough to excite a cell B and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that As efficiency, as one of the cells firing B, is increased."
We can rewrite this quote into something more familiar in today's machine learning world 3.
$$ \Delta w_i = \eta x_i y $$
where \(\Delta w_i\) is change of \(i\)'th neuron synaptic weights, \(x_i\) is the input, \(y\) is the postsynaptic response and \(\eta\) denotes learning rate. This rule is called Hebbian Learning Rule and Donald Hebb is considered as the father of neural networks.
Nevertheless, the unit which much more resembles present-day perceptron was invented by Frank Rosenblatt in 1958. One of the problems with McCulloch Pitts neuron was the fact that weights and thresholds could be determined only analytically. Rosenblatt brought a perceptron which weights and thresholds could be determined analytically or by a learning algorithm. Perceptron, similarly to MCP, takes some binary inputs and, using real weights to denote importance of each input, it produces the binary output based on particular threshold value. Today we usually put it in a following formula:
$$
y =
\begin{cases}
1, & \text{if} \quad \sum^n_{i=1} w_i x_i \geq \theta \\
0, & \text{otherwise}
\end{cases}
$$
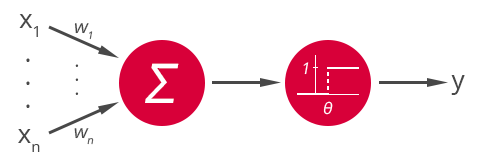
Figure 2. Perceptron model.
What is interesting, Rosenblatt's perceptron was not just a theoretical model, but it was an electronic device, which was intended to do image recognition.
One of the issues with perceptron was that it can only classify things that are linearly separable (classes can be separated by a hyperplane). The most famous limitation of the perceptron is its inability to learn XOR function, which was proved in 1969 by Marvin Minsky and Seymour Papert in a book "Perceptrons". The main controversy about this book is that it is supposed to be the main trigger of so called AI winter. When people realized that their expectations for AI were oversized, most funding for AI had been frozen, number of publications started to drastically decrease and AI itself was perceived as kind of pseudo science.
The pitfalls of perceptron could have been overcome by placing perceptrons side by side and stacking such layers one upon the other. This is better known as multi-layer perceptron (MLP). However, it was not clear how to efficiently train such model in order to find correct weights. It is commonly said that interest in AI came back after publishing "Learning representations by back-propagating errors" 4 by David Rumelhart, Geoffrey Hinton and Ronald Williams in 1986. They announced the discovery of a method allowing to effectively train multi-layer networks. Nevertheless, the honor of discovering backpropagation belongs to Paul Werbos who described this technique in 1974. One remarkable feature of MLP is that it can represent any function - such feature is called universal approximation property.
Impressive potential of neural networks had been shown by Yann LeCun in 1990, when he presented convolutional neural network (CNN) able to recognize handwritten and machine-printed digits. It was called LeNet-5 and the site is still available on LeCun's website 5. Unfortunately, there was another problem around the corner - scalability. Computing capabilities, required to train large neural networks, back in 90s were simply insufficient.
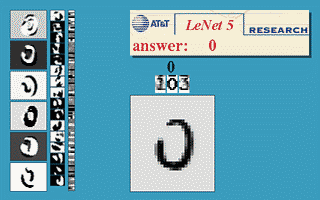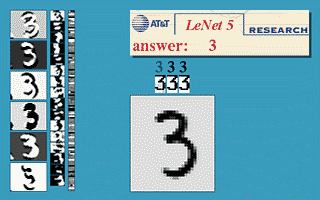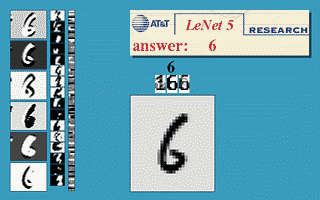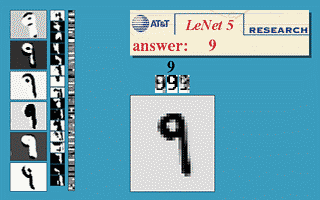
Figure 3. LeNet created by Yann LeCun. It was designed to recognize handwritten and machine-printed characters.
(source: yann.lecun.com/exdb/lenet/)
It is said that modern era of deep learning started in 2006, when Geoffrey Hinton introduced Deep Belief Networks and layer-wise pretraining technique 6. He showed how to stack Restricted Boltzman Machines (RBM) and train them in a greedy manner, treating consecutive layers as separate RMBs. We can assume that 2006 was a year when the term deep learning started to gain enormous popularity.
Today we have vast number of neural networks architectures, techniques and algorithms that underlie deep learning brand. Everyday great deal of new papers arrive and new possibilities of deep learning amaze us. There are several factors which made such state of affairs possible. Andrew Ng in his coursera deep learning course 7 talks about some of them:
- we have computation ability to take advantage of neural networks,
- we have a lot of data required to train neural networks,
- we have seen tremendous algorithmic innovation, which let us run neural networks much faster,
- we managed to deal with vanishing gradient problem,
- we have a lot of frameworks and tools, which help us to experiment faster.
Andrew Ng said that "it is all about scale" and he illustrated this statement using following chart during Extract Data Conference. I think it shows huge potential of deep learning.
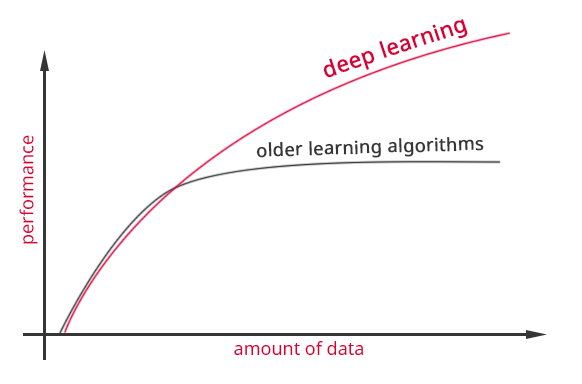
Figure 4. Why deep learning? How do data science techniques scale with amount of data?
(based on Andrew Ng slides slideshare.net/ExtractConf)
What's Deep in Deep Learning
All right, we already know where deep learning came from, but what deep learning actually is? Great explanation is provided by Ian Goodfellow in his "Deep Learning" 8 book. Deep learning allows computers to learn from experience and understand the world in terms of a hierarchy of concepts, with each concept defined in terms of its relation to simpler concepts. It allows computers to solve problems intuitive for all of us, but hard to describe formally e.g. detecting objects on images, generating a speech, translating from one language to another etc.
We can think of above explanation in terms of neural network layers. Each consecutive neural network layer learns some concept from data and provide it to the next layer, which learns some more abstract concept. We can continue this "concepts building" procedure over and over until we get several dozen of such layers. This idea is presented on the image below, where we try to classify an object on the image, which was passed to the network.
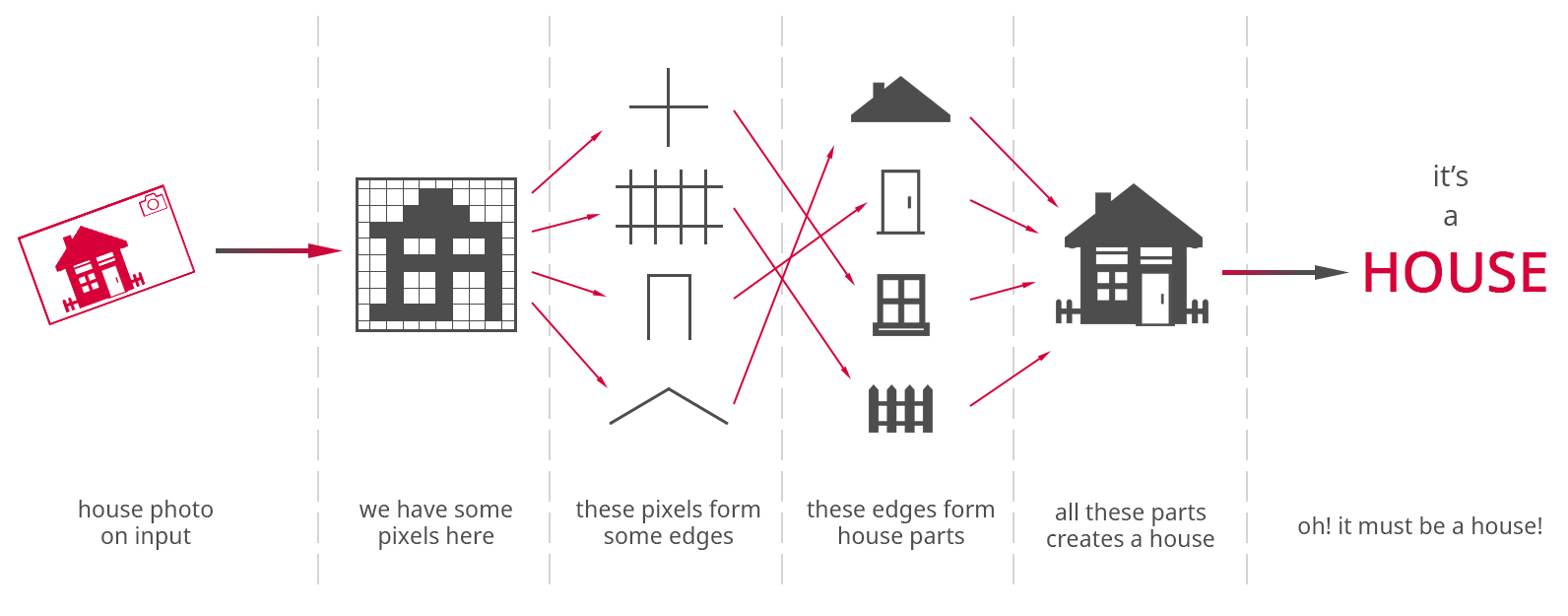
Figure 5. Simplified visualization of the idea of hierarchy of concepts within a neural network.
Presented image is just a simplification to help one understand how it works. In reality individual layers and units usually are not so easily interpretable and rarely they learn so well defined concepts. What is important here to remember is that individual layers learn hierarchy of concepts, which help predict the output. In this case an object on the input image.
Using classic machine learning algorithms to create some model, we need to conduct a labor intensive feature engineering. For instance, if we would like to predict what is on the image, we would need to extract in some way the features of such image. Such features are for example groups of pixels with similar color, spatial relationships between these groups, edges etc. Having bunch of these features we put them into our machine learning classifier and hopefully get some label on the output. This makes classic machine learning algorithms very representation dependent. The promise of deep learning is to perform this process automatically i.e. as a part of network learning process. We just need to provide a raw input, in this case it would be a matrix of pixels. Deep learning model would figure out its own data representations based on simpler representations i.e. those learned in preceding layers.
In that case, what is depth in terms of deep learning? Here I am going to refer to Ian Goodfellow book 8 again. He has written about two main ways of measuring the depth. The first one is the depth of the computational graph, the second is the depth of the probabilistic modeling graph. In the former one, we count the number of sequential instructions that must be performed to evaluate the architecture. What it means is the longest path through our network architecture. Frequently it would be simply number of layers in the network. The latter approach is about the number of related concepts connected to each other in order to compute the output. We can think of it in terms of above image. We have there pixels, edges, house parts and house itself - these adds up to 4 concepts. Number of layers required to build up these concepts might be larger than 4, thus the lonegst path would be larger than 4.
Is It Just About Neural Networks?
What I have noticed is that the answer to this question heavily depends on the definition of neural network and how someone understands it. Some people would say that deep learning consists in composing machine learning models that learn hierarchies of data representations. Others say that deep learning is just about neural networks with more than 1 hidden layer.
Neural networks are strictly related to the approach called connectionism, which the main idea is that a large number of simple computational units can describe some mental phenomena - just like our brain do it. This idea, emerged from neuroscience, gave some coarse guidelines on how to build neural networks, but modern deep learning techniques often goes beyond the human brain perspective. This is the reason why some people claim that neural network is a bit misleading name.
Let's take a quick look at what deep learning experts have to say. For instance, Yoshua Bengio and Yann LeCun in "Scaling Learning Algorithms towards AI" 9 write:
"Deep architectures are perhaps best exemplified by multi-layer neural networks with several hidden layers. In general terms, deep architectures are composed of multiple layers of parameterized non-linear modules. The parameters of every module are subject to learning."
In my opinion it suggest that there is something more than just neural networks. Furthermore, in "Deep Learning" 10 article by Yann LeCun, Yoshua Bengio and Geoffrey Hinton they explain:
"Representation learning is a set of methods that allows a machine to be fed with a raw data and to automatically discover the representations needed for detection or classification. Deep-learning methods are representation-learning methods with multiple levels of representation, obtained by composing simple but non-linear modules that each transform the representation at one level (starting with the raw input) into a representation at a higher, slightly more abstract level. With the composition of enough such transformations, very complex functions can be learned."
Again we read about building hierarchical model with multiple levels of representation. Given the fact that this is what deep learning stars say, I would stick to this explanation.
Summary
Undoubtedly deep learning has much longer history than its name has. This history shows that development of AI started because of fascination with human mind and its abilities. Therefore there is a lot of signs that the way human brain works is an inspiration in conceiving some ideas. Nevertheless, modern deep learning techniques are rather not designed to recall the brain, however the term neural networks already caught on and it is not likely to change.
To put it shortly, deep learning is all about learning multiple levels of representation. These levels consecutively create more and more abstract representations of provided data. Deep learning model learns to build a hierarchy of concepts, deriving more complex concepts from the simpler ones.
Further Reading
If you would like to read more on some topics addressed in this post, here are texts that explain them more comprehensively.
Deep Learning History - I really enjoyed reading "Deep Learning 101 - Part 1: History and Background" 11, "A 'Brief' History of Neural Nets and Deep Learning" 12 and "Deep Learning in a Nutshell: History and Training" 13. These articles provide much more information about the history of deep learning as well as a whole artificial intelligence field.
Who Was The First One? - Gathering materials to write this post I found out that there is some issue regarding who should be credited for inventing particular methods, algorithms and ideas. You can find more in "Critique of Paper by "Deep Learning Conspiracy"" 14. Also, interesting information can be found in "On the Origin of Deep Learning" 3.
Deep Learning Definition - In addition to books and articles I have already mentioned in this post, there is a question on Quora regarding "What is the difference between Neural Networks and Deep Learning?". I consider all answers worth reading. A great article is also provided by Jason Brownlee in "What is Deep Learning?" 15.
References
-
Amanda Gefter, "[The Man Who Tried to Redeem the World with Logic][11]", Naulitus, 2015 ↩
-
Warren McCulloch, Walter Pitts, _"A logical calculus of the ideas immanent in nervous activity", The bulletin of mathematical biophysics 5.4, 1943 ↩
-
Wang, Haohan, Bhiksha Raj, and Eric P. Xing, "On the Origin of Deep Learning" arXiv, 2017 ↩ ↩
-
David E. Rumelhart, Geoffrey E. Hinton and Ronald J. Williams, "Learning representations by back-propagating errors.", Nature 323.6088, 1986 ↩
-
[LeNet-5, convolutional neural networks][3] ↩
-
Geoffrey Hinton, Simon Osindero, and Yee-Whye Teh, "A fast learning algorithm for deep belief nets", Neural computation 18.7, 2006 ↩
-
[Deep Learning Specialization][4], Coursera ↩
-
Ian Goodfellow, Yoshua Bengio, and Aaron Courville, "Deep learning", MIT press, 2016 ↩ ↩
-
Yoshua Bengio,and Yann LeCun, "Scaling learning algorithms towards AI", Large-scale kernel machines 34.5, 2007 ↩
-
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton, "Deep learning", Nature 521.7553, 2015 ↩
-
Andrew L. Beam, "[Deep Learning 101 - Part 1: History and Background][6]", 2017 ↩
-
Andrey Kurenkov, ["A 'Brief' History of Neural Nets and Deep Learning"][7], 2015 ↩
-
Tim Dettmers,["Deep Learning in a Nutshell: History and Training"][8], 2016 ↩
-
Jürgen Schmidhuber, "[Critique of Paper by "Deep Learning Conspiracy"]"[9], 2015 ↩
-
Jason Brownlee, ["What is Deep Learning"][10], 2016 ↩
Also published on Medium.